
Byte Insight: Exploring Data Modeling Architectures - Medallion, Star Schema, and Data Vault
Understanding the Strengths, Weaknesses, and Use Cases of Popular Data Engineering Frameworks.

Data modeling is the heart and soul of every data engineering solution, determining how data is structed, stored and analysed. In this post we’ll compare three popular architectures: Medallion, Star Schema and Data Vault. Each method has it’s own unique strengths, weaknesses and use cases.
Medallion Architecture
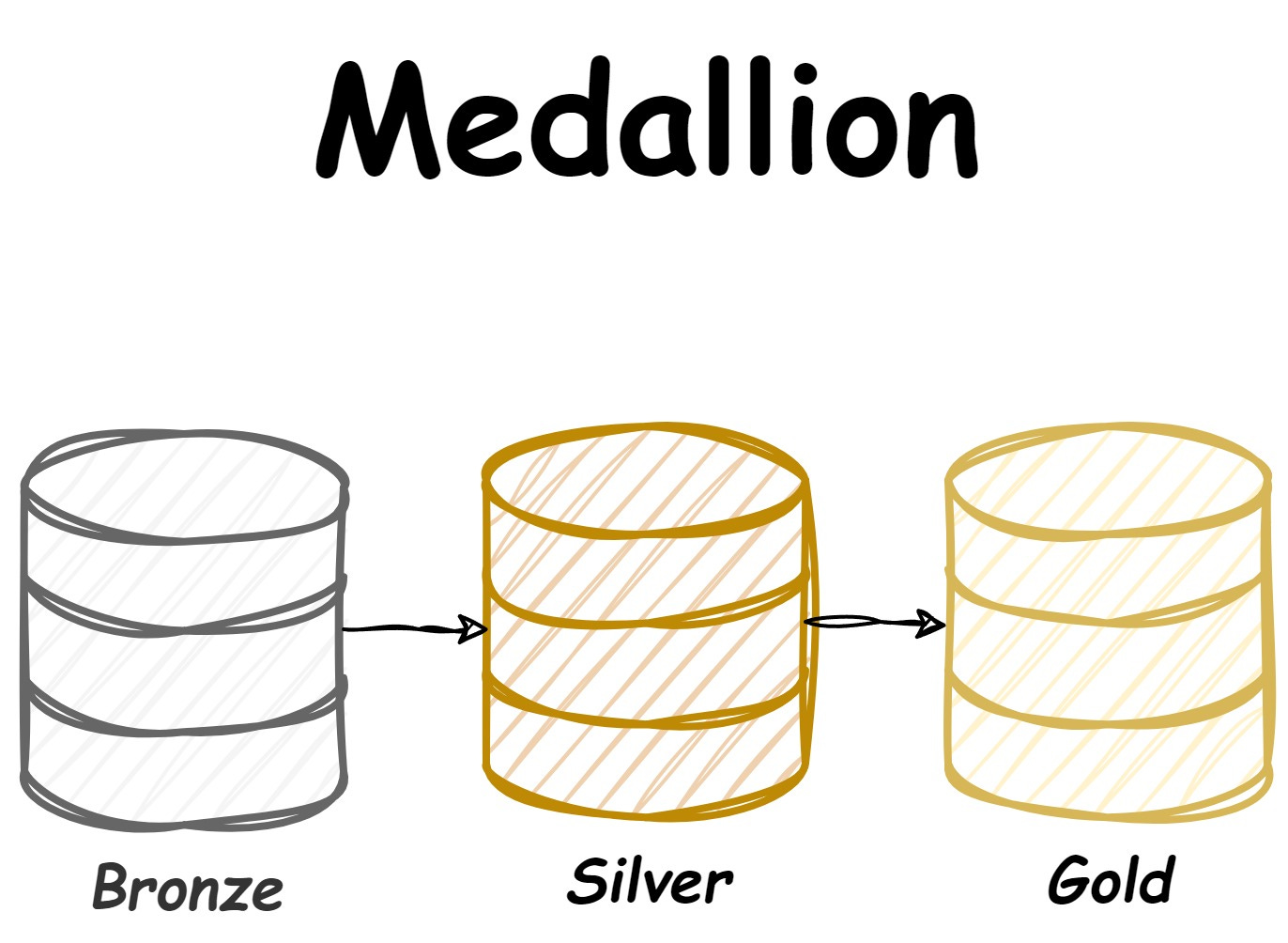
The Medallion Architecture organises data into three layers: Bronze, Silver, and Gold. It’s often used in modern lakehouse architectures like Databricks, focusing on scalability and data lineage.
How does it work?
Bronze Layer: Stores raw, unprocessed data directly from source systems. These can be extracts from databases, json files, csv files, even event data in avro format!
Silver Layer: Transforms and cleanses data to create a more usable intermediate layer. So, assigning data types, value cleansing and sometimes light modeling.
Gold Layer: Contains refined, analytics-ready data for Business Intelligence (BI) and reporting. Essentially, aggregated datasets dependent on use cases and specific business questions that need answering
The Benefits
Data Lineage: Tracks data transformations across layers.
Flexibility: Supports both historical data retention and near real-time analytics.
Scalable: Works well with both batch and streaming data (providing you’ve set up your processes in the background correctly!)
The Drawbacks
Processing Time: It typically involves multiple layers of data (Bronze, Silver, Gold), with data stored redundantly in various stages of transformation, increasing storage costs.
Increased Storage/Maintenance Overhead: Data flows through multiple layers, with transformations applied at each stage. For example, raw data is ingested into Bronze, cleansed and enriched in Silver, and aggregated or modeled in Gold.
Star Schema

The Star Schema is a common data modelling method in data warehouses. Designed for simplicity and fast querying. It consists of fact tables (storing numeric data) connected to dimension tables (storing descriptive attributes).
How does it work?
Fact Tables: Contains metrics for measures, such as sales or revenue, linked by foreign keys to dimension tables.
Dimension Tables: Contains descriptive content, such as customer details, product information or time periods.
The Benefits
Query Performance: Optimised for aggregation and analysis.
Ease of Use: Easy to understand for non-technical users.
Simplicity: Reduces complexity compared to highly normalised schemas.
The Drawbacks
Less Flexibility: takes time to set up and maintain, especially with small teams with limited resource.
Limited Scalability: Star schema is designed for simplicity, with one fact table surrounded by directly related dimension tables. It doesn’t handle many-to-many or complex hierarchical relationships well.
Data Vault
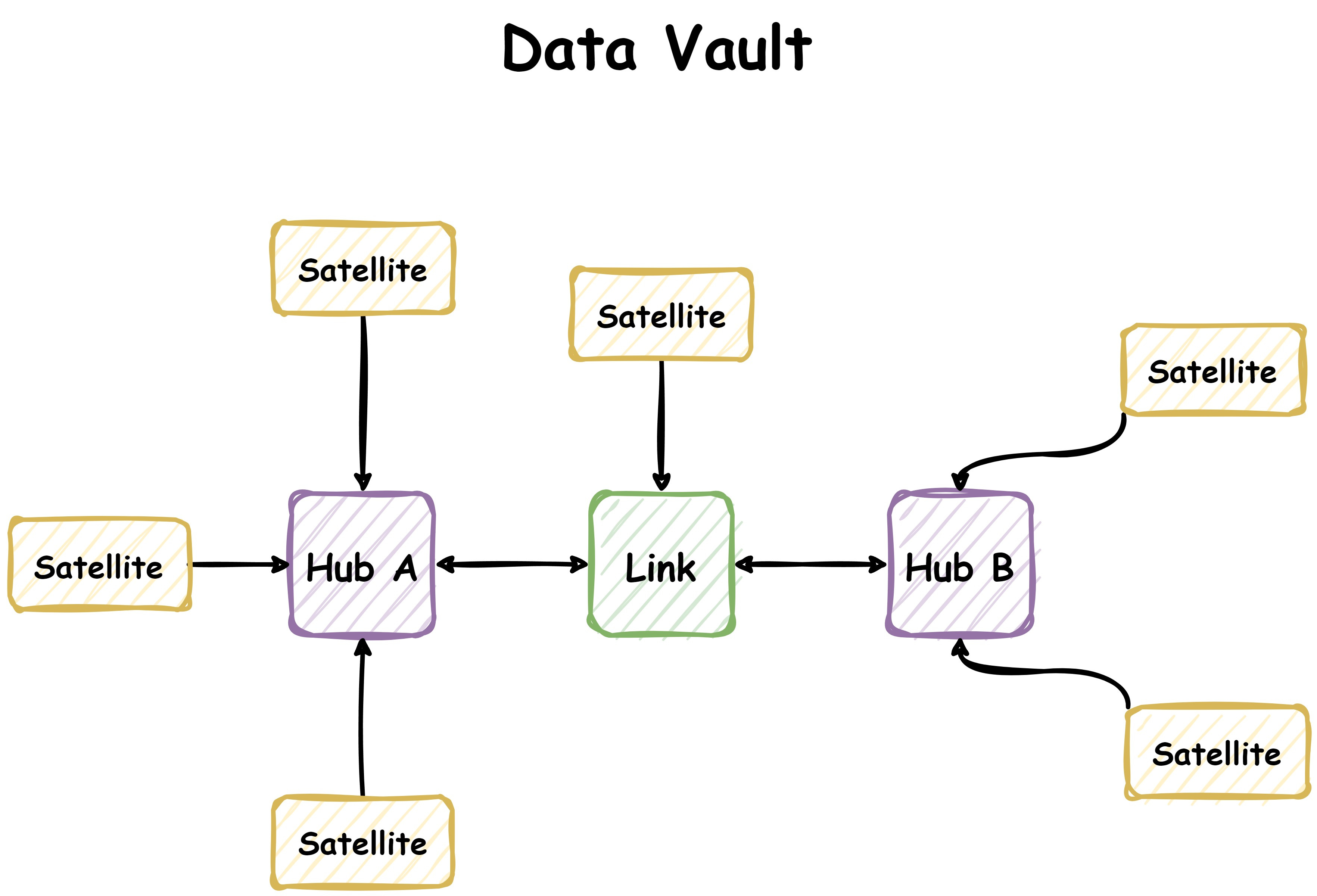
The Data Vault approach is actually one of my favourites. Emphasising on scalability, flexibility, and historical accuracy. It organises data into Hubs, Links and Satellites to separate core entities, relationships and descriptive attributes.
How does it work?
Hubs: Represents unique business keys. For example; Customer ID, Store ID, Order ID.
Links: Stores relationship between business keys. So, the relationship between a customer and an order.
Satellites: Capture descriptive attributes and historical changes for the hubs and links. This pertains to address data, contact details and potentially the record source itself.
The Benefits
Auditable: Built-in support for tracking historical changes.
Scalable: Easily scales when dealing with large datasets.
Adaptable: Handles schema changes without reworking the model.
The Drawbacks
Complex: takes time to set up and maintain, especially with small teams with limited resource.
Potential Performance Issues: Model is heavily normalised which means even simple queries require multiple joins. This can affect query performance especially on large datasets if you don’t have the correct infrastructure in place.
The Takeaway
All-in-all, each architecture is tailored to a specific use case. Use the Medallion architecture for scalable, end-to-end data processing in modern lakehouses. Data Vault for compliance and historical tracking, and Star Schema for intuitive, high-performance BI applications!
You just need to select the one that aligns with the size of your team as well as your organisational needs.
So, with all that in mind:
Cheers for reading my blog! If you want to see more content like this, hit the subscribe button below
Hi, in the data vault model: where are the facts tables stored ? in the Hub? How would you organize several fact tables?