
The Snowflake Review You've Been Waiting For
Thorough review of the Snowflake Platform


Snowflake has built a reputation as one of the most widely adopted cloud data platforms. It is easy to spin up, it scales elastically, and it has strong features for analytics. But what happens when you look past the webinars and focus on what actually matters for engineering teams building modern, AI-ready data platforms?
In this review I’ll take a deeper dive into Snowflake with five lenses: AI-readiness, data engineering, repo integration, access and security, and batch vs real-time streaming. These are the areas that make or break whether Snowflake is the right fit for an enterprise data strategy.
AI-Readiness
One of the key questions today is whether your data platform can serve as the foundation for AI initiatives. Snowflake positions itself well in terms of data accessibility: it handles structured and semi-structured data (JSON, Avro, Parquet) natively, and with features like Snowpark you can push some ML workloads closer to your data.
Where Snowflake falls short is in end-to-end AI pipelines. Unlike Databricks, it doesn’t natively provide model training or ML lifecycle management. That means if your strategy is AI-first, you’ll still need to integrate external services such as SageMaker, Azure ML, or Databricks for feature engineering, training, and deployment.
That said, Snowflake does excel in being a data foundation for AI. It centralises clean, governed data, makes it easy to share securely across teams, and provides SQL-first access for feature discovery. In short, Snowflake is “AI-ready” as a source of truth but not as a model factory.
Data Engineering
Snowflake is optimised for SQL-centric data engineering. ELT (extract, load, transform) is the default pattern: you load raw data into Snowflake and then transform it in place using SQL. With tools like dbt, you’re able to manage transformations effectively and keep pipelines versioned.
The challenge comes when you need complex transformations or streaming-first pipelines. Snowflake’s batch focus works well for dimensional modelling, reporting, and dashboarding. For heavy transformation logic, data cleansing, or schema evolution at speed, you’ll often find yourself leaning on Spark or Databricks alongside it, in my opinion.
Snowflake’s simplicity for analysts is its strength, but for engineering teams that are used to building modular, Pythonic pipelines and building for AI-first rather that reporting-first, it can feel restrictive. It’s excellent for “last mile” transformations, but not always the best fit for complex data wrangling at scale.
Repo Integration and CI/CD
Modern engineering practices focus around the ability to work and commit to data pipelines that live in repositories, with CI/CD processes governing changes. Snowflake doesn’t have native repo management. Instead, it integrates via tools like:
dbt for SQL model versioning and transformation orchestration.
Terraform for infrastructure as code.
GitHub Actions or Azure DevOps pipelines for deployment automation.
This works well in practice, but it means Snowflake relies heavily on its ecosystem. There isn’t a “Snowflake-native” DevOps model. If you’re looking for a tightly integrated repo-driven workflow, you’ll need to build it yourself.
On the plus side, Snowflake’s CLI and API support are solid, and many teams already standardise on dbt, which makes Snowflake a natural fit for declarative SQL-first DevOps.
Access and Security
To be honest, Snowflake deserves real credit here. Security is baked into its product:
Role-based access control (RBAC) with granular permissions.
Always-on encryption at rest and in transit.
Support for SSO, MFA, and federated identity via your existing identity provider.
Compliance certifications across GDPR, HIPAA, PCI DSS and more.
For enterprises, this means Snowflake is ready for regulated workloads. But the real differentiator is data sharing security. You can grant external partners access to live datasets without moving or duplicating data. That cuts down on risk and keeps governance centralised.
Where it can get tricky is in fine-grained access at column or row level. While Snowflake does support it, it takes careful design. You need a clear data governance model, otherwise RBAC can become a sprawl of roles and grants.
Batch vs Real-Time Streaming
This is where expectations and reality unfortunately diverge. Snowflake is fundamentally a batch-first platform. It’s fantastic for scheduled ingestion, batch ETL, and analytics workloads where data freshness is measured in minutes or hours.
Snowpipe, Snowflake’s streaming ingestion service, allows near-real-time ingestion of small files, but it’s not a fully fledged streaming engine like Kafka or Azure Event Hubs. Latency is still measured in seconds to minutes, not milliseconds.
If your use case demands true streaming pipelines (fraud detection, IoT telemetry, recommendation engines, Loyalty), Snowflake should be paired with a streaming technology. Snowflake can act as the system of record or long-term storage, but not as the stream processor.
Data Bytes & Insights Verdict
When viewed through these five lenses I feel are the most important these days, Snowflake is a platform that excels at simplifying access to governed data. It’s perfect for enterprises looking to modernise their analytics estate, adopt ELT pipelines, and prepare clean datasets for AI initiatives.
But it’s not the one-stop-shop some believe it to be. For real-time streaming, advanced ML pipelines, and repo-driven engineering maturity, you’ll need to stitch Snowflake into a broader ecosystem.
In other words: Snowflake is a strong branch, not the whole Tree.
The 5 Point Diagram
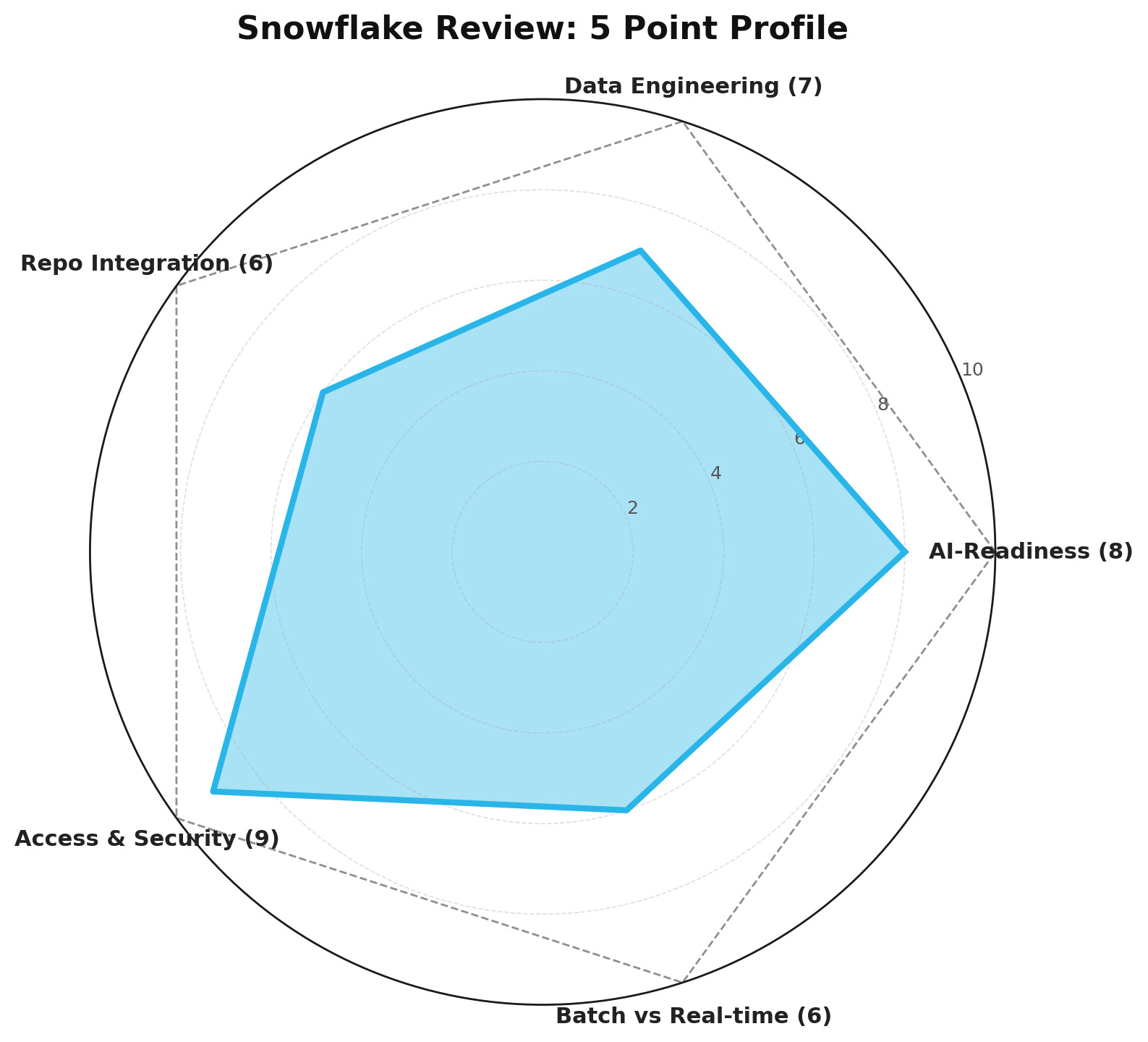
AI-Readiness: 8/10
Data Engineering: 7/10
Repo Integration: 6/10
Access & Security: 9/10
Batch vs Real-time: 6/10
My score: 7/10
Strong on governance, security, and AI-readiness as a data source.
Less compelling for real-time AI-first workloads or heavy-duty engineering pipelines.
Very poorly informed article. I think you may have missed out on many key products that are announced a while ago.