
Day 28 of 50 Days of Python: Introduction to PySpark for Big Data Processing.
Part of Week 4: Python for Data Engineering


Welcome to the final day of the Python for Data Engineering week, Day 28. The reason for this hijack is because there comes a time where traditional Python methods for handling large datasets often becomes inefficient. PySpark, the Python API for Apache Spark, provides a powerful solution for big data processing. Spark’s distributed computing capabilities allow it to process vast amounts of data in parallel, making it a go-to tool for data engineers and data scientists dealing with large-scale analytics.
In this post, I’ll take you through the advantages of PySpark over standard Python, define what qualifies as big data, and discuss an additional key concept: optimising performance in PySpark.
Python vs PySpark for Big Data Processing
Python is a great language for data processing, but when it comes to handling terabytes or petabytes of data, it faces HUGE performance bottlenecks. PySpark, on the other hand, leverages Apache Spark’s distributed computing framework to efficiently process large datasets. Here’s a side-by-side comparison:
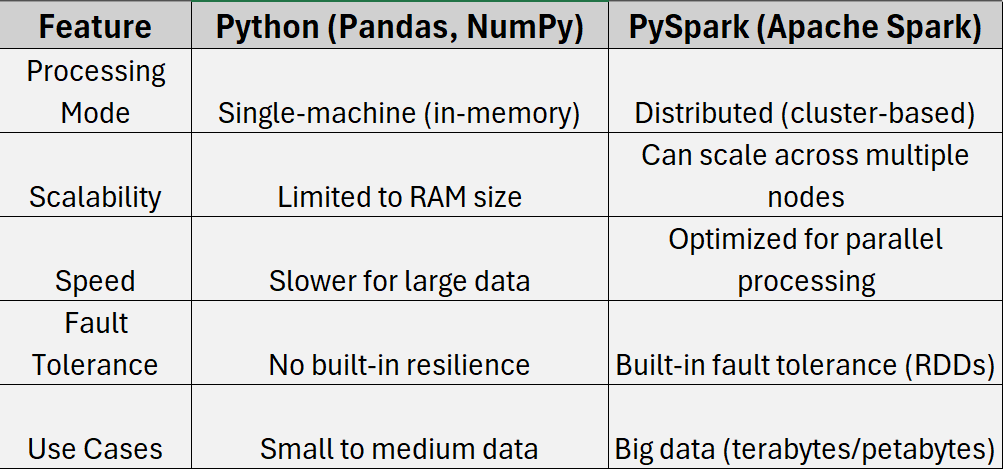
As you can see from the features in the table above, PySpark is the ideal choice when data sizes exceed a single machine’s memory or when computations need to be distributed across multiple nodes.
When is Data Considered Big Data?
Big data isn’t just about volume—it’s defined by the three Vs:
Volume – Data that is too large to be processed on a single machine (e.g., terabytes or more).
Velocity – Data that is generated and processed at high speeds, requiring real-time or near-real-time analytics (e.g. streaming data from IoT sensors or Azure Event Hubs).
Variety – Data that comes in different formats, including structured (SQL tables), semi-structured (JSON, XML), and unstructured (text, images, videos).
When your data exceeds the limits of traditional data processing tools and meets any of the three Vs, it’s time to consider using PySpark.
Optimising Performance in PySpark
To get the most out of PySpark, optimising performance is key to the process. Here are some best practices to follow when structuring your scripts:
Use DataFrames Instead of RDDs – DataFrames are optimised for performance, leveraging Spark’s Catalyst optimiser and Tungsten execution engine.
Leverage Partitioning – Ensuring data is evenly distributed across nodes prevents bottlenecks.
Cache and Persist Data – If data needs to be reused, caching reduces recomputation overhead.
Optimise Shuffle Operations – Minimising data shuffling across nodes improves efficiency.
Use Broadcast Variables – Reducing data transfer overhead for small datasets improves speed.
By implementing these strategies, you can significantly enhance PySpark’s efficiency and make big data processing even faster.
Next Up: Day 29 - Introduction to Pandas for Data Analysis
Day 29 is the start of of week 5, Data Analysis and Visualisation. We’ll start off the week exploring one of Python’s most widely used libraries for data analysis, Pandas. Touching on how it enables efficient manipulation, transformation, and analysis of structured data. Whether you’re dealing with CSV files, SQL tables, or large datasets, Pandas provides an intuitive API for data cleaning and aggregation.
So stay tuned for week 5, and happy coding!
