
Day 25 of 50 Days of Python: Building ETL Pipelines in Python
Part of Week 4: Python for Data Engineering

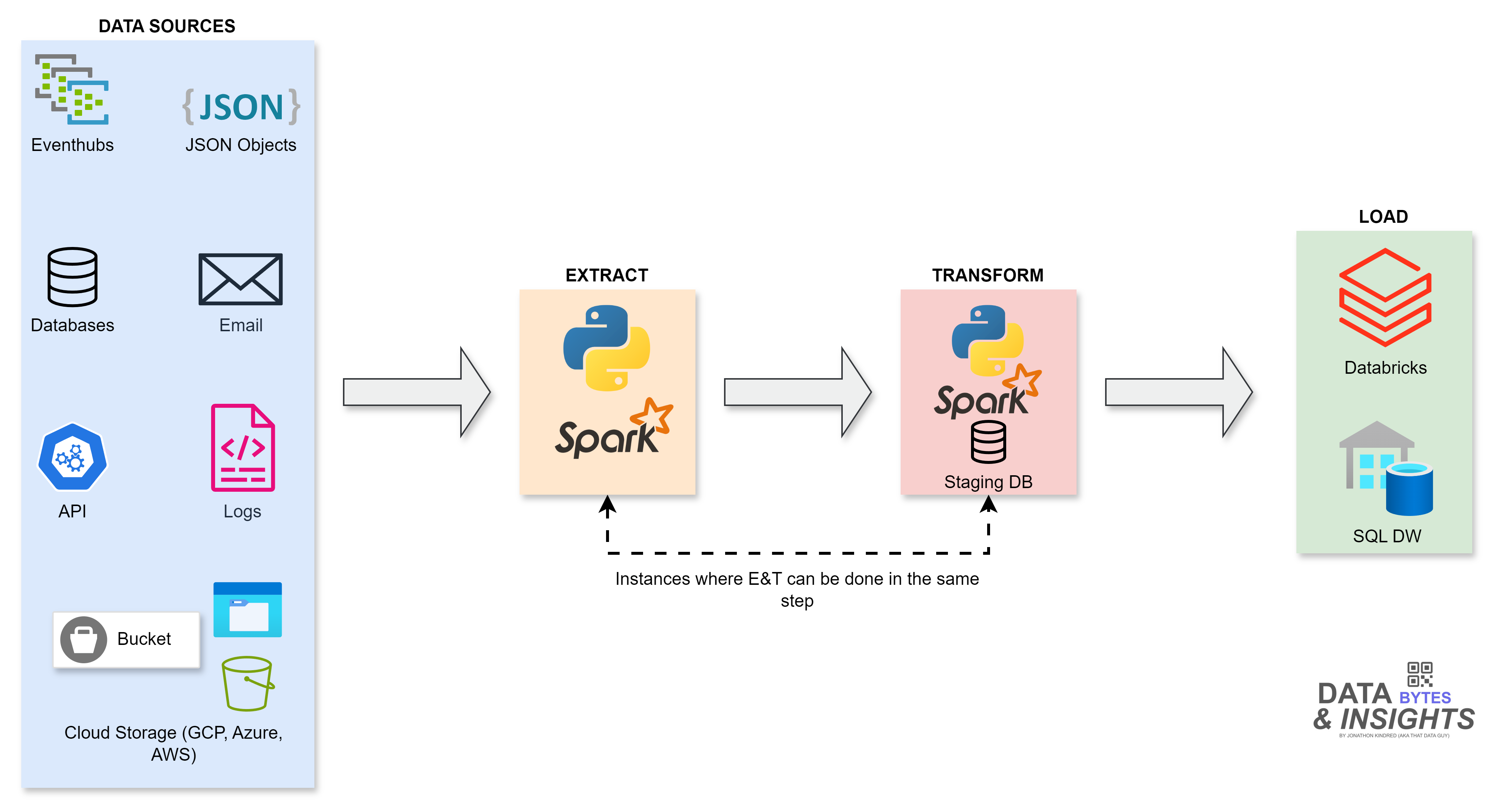
Welcome to Day 25! Where we move into one of the most critical skills for data engineers and analysts: building ETL pipelines. ETL stands for Extract, Transform, Load, and it’s the process of moving data from one or more sources, transforming it into a usable format, and loading it into a destination system (like a database or data warehouse).
What we’ll be focusing on in todays post is building a simple ETL pipeline that:
Extracts data from the Spotify API.
Transforms the data into a structured format.
Loads the data into a SQLite database.
By the end of this post, you’ll have a basic ETL pipeline that you can adapt for your own projects.
What is an ETL Pipeline?
I’ve touched on this a few times in previous posts, but to save you clicking through my other articles, I’ll cover it here too!
As stated above, an ETL pipeline consists of 3 steps: Extract-Transform-Load.
→ Extract: Pulling data from various sources such as APIs, Databases and even cloud storage.
→ Transform: Clean, filter, and structure your data for analysis and storage.
→ Load: Save the transformed data into a destination like a database, data warehouse or even just a file in storage.
Step 1: Extract Data using Spotify API
We’ll use the Spotify API to fetch data about Drake, including his top tracks, albums, and artist details. Here’s how to authenticate and extract data:
pip install spotipy # If neededimport spotipy
from spotipy.oauth2 import SpotifyOAuth
# Spotify API credentials
SPOTIPY_CLIENT_ID = 'your_client_id'
SPOTIPY_CLIENT_SECRET = 'your_client_secret'
SPOTIPY_REDIRECT_URI = 'http://localhost:8888/callback' # Must match your Spotify app settings
# Authenticate with Spotify
sp = spotipy.Spotify(auth_manager=SpotifyOAuth(
client_id=SPOTIPY_CLIENT_ID,
client_secret=SPOTIPY_CLIENT_SECRET,
redirect_uri=SPOTIPY_REDIRECT_URI,
scope='user-library-read'
))
# Fetch Drake's artist data
def extract_drake_data():
# Search for Drake
results = sp.search(q='artist:Drake', type='artist', limit=1)
drake = results['artists']['items'][0]
return {
'artist_id': drake['id'],
'name': drake['name'],
'genres': ', '.join(drake['genres']),
'popularity': drake['popularity'],
'followers': drake['followers']['total']
}
# Fetch Drake's top tracks
def extract_top_tracks(artist_id):
results = sp.artist_top_tracks(artist_id)
return [{
'track_id': track['id'],
'name': track['name'],
'duration_ms': track['duration_ms'],
'explicit': track['explicit'],
'popularity': track['popularity'],
'album_id': track['album']['id']
} for track in results['tracks']]
# Fetch Drake's albums
def extract_albums(artist_id):
results = sp.artist_albums(artist_id, album_type='album', limit=10)
return [{
'album_id': album['id'],
'name': album['name'],
'release_date': album['release_date'],
'total_tracks': album['total_tracks']
} for album in results['items']]Step 2: Transform the Data
Once we’ve extracted the data, we need to transform it into a structured format suitable for our databases schema. Here’s how you’d transform data using Python, following the functional programming paradigm:
def transform_artist_data(artist_data):
return (
artist_data['artist_id'],
artist_data['name'],
artist_data['genres'],
artist_data['popularity'],
artist_data['followers']
)
def transform_track_data(track_data):
return (
track_data['track_id'],
track_data['name'],
track_data['duration_ms'],
track_data['explicit'],
track_data['popularity'],
track_data['album_id']
)
def transform_album_data(album_data):
return (
album_data['album_id'],
album_data['name'],
album_data['release_date'],
album_data['total_tracks']
)Step 3: Load the Data into SQLite
The final step is to load the transformed data into our SQLite database. Here’s how to do this:
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('drake.db')
cursor = conn.cursor()
# Create tables
cursor.execute('''
CREATE TABLE IF NOT EXISTS Artists (
artist_id TEXT PRIMARY KEY,
name TEXT,
genres TEXT,
popularity INTEGER,
followers INTEGER
)
''')
cursor.execute('''
CREATE TABLE IF NOT EXISTS Albums (
album_id TEXT PRIMARY KEY,
name TEXT,
release_date TEXT,
total_tracks INTEGER
)
''')
cursor.execute('''
CREATE TABLE IF NOT EXISTS Tracks (
track_id TEXT PRIMARY KEY,
name TEXT,
duration_ms INTEGER,
explicit BOOLEAN,
popularity INTEGER,
album_id TEXT,
FOREIGN KEY (album_id) REFERENCES Albums(album_id)
)
''')
# Load artist data
def load_artist_data(artist_data):
cursor.execute('''
INSERT OR IGNORE INTO Artists (artist_id, name, genres, popularity, followers)
VALUES (?, ?, ?, ?, ?)
''', artist_data)
conn.commit()
# Load album data
def load_album_data(album_data):
cursor.execute('''
INSERT OR IGNORE INTO Albums (album_id, name, release_date, total_tracks)
VALUES (?, ?, ?, ?)
''', album_data)
conn.commit()
# Load track data
def load_track_data(track_data):
cursor.execute('''
INSERT OR IGNORE INTO Tracks (track_id, name, duration_ms, explicit, popularity, album_id)
VALUES (?, ?, ?, ?, ?, ?)
''', track_data)
conn.commit()Putting It All Together in a ETL Pipeline
def main():
# Step 1: Extract
drake_data = extract_drake_data()
top_tracks = extract_top_tracks(drake_data['artist_id'])
albums = extract_albums(drake_data['artist_id'])
# Step 2: Transform
transformed_artist_data = transform_artist_data(drake_data)
transformed_tracks = [transform_track_data(track) for track in top_tracks]
transformed_albums = [transform_album_data(album) for album in albums]
# Step 3: Load
load_artist_data(transformed_artist_data)
for album in transformed_albums:
load_album_data(album)
for track in transformed_tracks:
load_track_data(track)
# Close the database connection
conn.close()
if __name__ == '__main__':
main()To run this pipeline replace the client secret with the details from your Spotify developer account we created at the beginning of this weeks content. Then run the script within your CLI:
python drake_etl_pipeline.pyQuerying Your Newly Formed Tables
Get Drake’s Top Tracks:
SELECT t.name, t.popularity, a.name AS album FROM Tracks t JOIN Albums a ON t.album_id = a.album_id ORDER BY t.popularity DESC;Get Drake’s Albums:
SELECT name, release_date, total_tracks FROM Albums;
Next Up: Day 26 - Working with APIs and Web Scraping using requests and BeautifulSoup.
Day 26 will see us working with APIs and Web Scraping using requests and BeautifulSoup. We’ll explore how to extract data from websites and APIs, building on today’s ETL pipeline skills as well as having a head start with APIs due to our work with pulling Drake’s metrics!
See you soon for Day 26, and happy coding.

Some explanation for the code would be helpful. There's no comments, and there's little documentaiton in the spotipy module for what any of these functions expect in terms of the underlying data structures that get returned. The spotipy api docs doesn't give much info either.
FWIW, here's the error when you run this in a script. I filled the client_id and secret from my spotipy account just like you said. The redirect uri is the set to match the one in the code. It chokes on the extract_drake_data() function where it calls the sp.search() function.
spotipy:exceptions.SpotifyOauthError: Server listening on localhost has not been accessed
Or: my browser gets redirected to a link that says the page cannot be accessed.